Each
time day to day work life of an employee or an organization depend on raw data
from different sources. Data was the base for create
information, using some instructions, formula or algorithm. We convert that set
of data in to set of information to get some scheduled output according to the
job or task. That was the simplest way of information generation through data
which need little or average computational capacity. This information gives much
more advance set of data than the raw data, which helps decisions making.
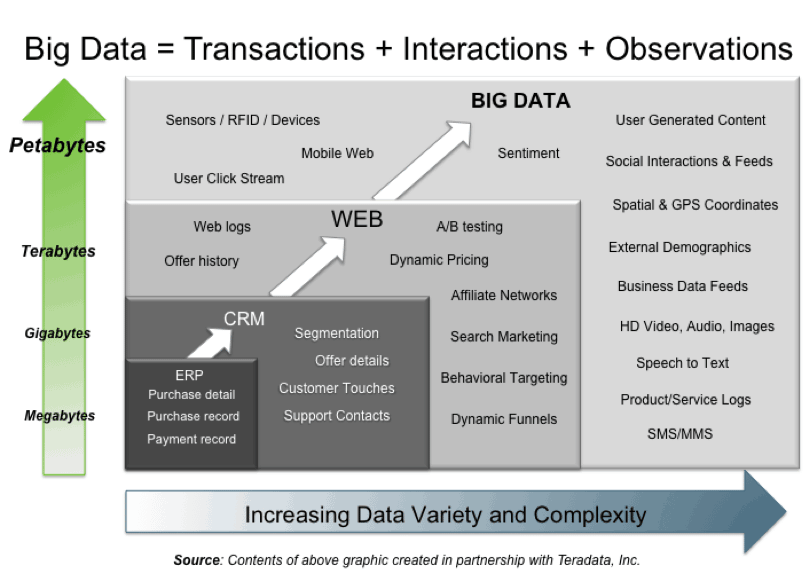
But in modern world
most of the data and information linked each other every time through internet,
we called it as networked data. Each data has own set of sub data or the reference
links, shares, likes, comments, attachments, notes with it. Therefore those set
of data had its own environment, which cannot separate data from its
environment. Through this collection of
data sets so large and complex that it becomes difficult to process using
on-hand database management tools or traditional data processing applications. These
kind of data sets we simply called as “big data”, because of its behavior and
capacity.

Big data that may help
to identify lots of trends, behaviors, patterns and so on. But the challenges include capture, curation, storage,
search, sharing, transfer, analysis, and visualization. The trend to
larger data sets is due to the additional information derivable from analysis
of a single large set of related data, as compared to separate smaller sets
with the same total amount of data. Big data is difficult to work with using
most relational database management systems and desktop statistics and
visualization packages, requiring instead "massively parallel software running
on tens, hundreds, or even thousands of servers".

Very informative and well written post! Quite interesting and nice topic chosen for the post.
ReplyDeleteAlienware Laptops